

Não há exagero nas manchetes: há uma semana, a firma chinesa de inteligência artificial DeepSeek deu uma guinada nesta área de corrida tecnológica entre civilizações ao publicar o “R1”, seu modelo grande de linguagem (LLM) em resposta ao modelo “o1”, o melhor no ChatGPT, da OpenAI.
O engenheiro de software e investidor americano Marc Andreessen chamou a inovação de “o momento Sputnik da IA”. É uma comparação apta, por dois motivos. Primeiro, o satélite soviético foi um pontapé inicial da corrida espacial da Guerra Fria — e o R1 colocou a China no mapa da IA como competidora em igualdade de condições com os Estados Unidos pela primeira vez.
Segundo, há o efeito psicológico. O Sputnik causou pânico e sobriedade no Ocidente por mostrar a capacidade da União Soviética de mandar um objeto — como uma bomba nuclear — a qualquer ponto do mundo. O R1 mostrou que é possível fazer muito com menos recursos — potencialmente, menos de US$ 10 milhões.
A notícia veio dias após Donald Trump anunciar um plano multibilionário em parceria com a OpenAI, Oracle, SoftBank (um banco japonês) e MGX (investidora dos Emirados Árabes). Chamado de projeto Stargate, o plano envolve a intenção de investir US$ 500 bilhões nos próximos quatro anos em infraestrutura para IA nos Estados Unidos.
Enquanto empresas americanas de IA como OpenAI, Google, Meta e Anthropic (dona do LLM Claude) precisam treinar seus robôs de conversação em computadores com 16 mil chips ou mais, a DeepSeek alega ter usado somente 2.048 chips de segunda categoria da Nvidia para treinar o R1.
Resultado: a fabricante de chips de computador Nvidia, uma das principais beneficiadas com a corrida da IA, sangrou US$ 600 bilhões em valor de mercado em uma semana, mais que o montante planejado de investimentos do Stargate.
A natureza e qualidade da inovação do DeepSeek-R1
O DeepSeek-R1 é um modelo “pensante”, no sentido de gerar, antes da resposta final a uma solicitação, um passo a passo explícito de como chegou à solução. O OpenAI-o1 também faz esse passo a passo, mas não o mostra ao usuário.
O que é um LLM ou robô conversacional com inteligência artificial? É uma versão muito turbinada do previsor de texto que observamos nos teclados dos nossos celulares, para simplificar. Um modelo deste tipo carrega números de probabilidade que codificam a “proximidade” de pedaços de texto com outros, criando um “espaço semântico” em que, se você pergunta o que é fascismo, ele já “sabe” que isso tem algo a ver com Hitler e Mussolini porque “viu” antes em muitos textos durante seu treinamento. Esses números são chamados de parâmetros e, até certo limite, quanto mais parâmetros, mais precisas são as respostas do LLM. Não há mágica, nem mesmo inteligência de fato: é matemática aplicada.
Uma forma de os LLMs melhorarem é com uma imitação do que se faz no treinamento de animais: reforço positivo e reforço negativo. É por isso que o ChatGPT coloca botões de “gostei” e “não gostei” para o usuário em toda resposta.
Um dos segredos do DeepSeek-R1 está nesses reforços. Outro está na forma como usa os seus 671 bilhões de parâmetros: eles são divididos em grupos que são como “especialistas” que são recrutados somente se a tarefa pedida está dentro de sua expertise. Não há necessidade de chamar o padeiro, se a pergunta trata somente de mecânica de automóveis. Por isso, cerca de 37 bilhões de parâmetros são recrutados por vez. O resultado disso é economia de tempo, energia e dinheiro.
O R1 é realmente muito bom. Em testes, se sai tão bem quanto o OpenAI-o1 e o Claude 3.5, às vezes melhor que ambos, em resolver 500 problemas aleatórios de matemática, passar em uma prova competitiva da área, escrever código de programação e outras tarefas padronizadas. O modelo é capaz de gerar o código para fazer o jogo da cobrinha dos celulares de duas décadas atrás em segundos e o jogo Tetris em minutos, acertando na primeira tentativa.
Como os modelos de IA no fundo são feitos de probabilidade e estatística, os próprios resultados que geram são variáveis. Um ranking que leva isso em conta, hospedado no respeitado portal especializado em IA Hugging Face, envolvendo 195 modelos e mais de dois milhões e meio de votos, coloca o DeepSeek-R1 no momento na terceira posição, dividida com a última versão do ChatGPT-4o e uma versão do Gemini. Na primeira e segunda posições estão versões premium do Gemini — parece que o Google, depois de comer poeira da OpenAI, está se recuperando na área.
Os testes objetivos, contudo, nem sempre capturam a qualidade completa de um LLM. Pode soar subjetivo, mas a “vibe” do uso prático também deve ser levada em conta. Nathan Lambert, um pesquisador de LLMs do Instituto Allen de Inteligência Artificial, depois de passar uma semana usando o modelo da DeepSeek, disse que “o caráter ou pós-treinamento mais raso do modelo faz parecer que ele tem mais a oferecer do que aquilo que ele entrega. É um modelo muito capacitado, mas não traz tanta satisfação quando é usado de forma similar ao Claude ou aplicativos tão polidos quanto o ChatGPT, então não tenho a expectativa de usá-lo no longo prazo”.
Usei o DeepSeek-R1 por algumas horas. Um teste que gosto de fazer com os modelos é uma pergunta muito específica sobre a história da teoria da evolução. Até a maioria dos biólogos costuma errar. (Não vou colocá-la aqui, para continuar podendo usar como teste.) A melhor resposta foi do ChatGPT com o OpenAI-o1, o DeepSeek-R1 respondeu bem, mas quase escorregando na casca de banana, e o Gemini na versão 2.0 Flash Experimental cometeu o exato erro que eu esperava. Nenhuma das respostas foi completamente exata.
Quem é a DeepSeek? Dá para confiar no que ela alega?
O nome em inglês que a empresa usa para se apresentar ao mundo é uma tradução do nome original em mandarim, “Exploração Profunda”. A firma é de propriedade de uma empresa de investimentos de risco, a High-Flyer, também chinesa. Ambas, estabelecidas em 2023, são administradas pelo empresário Liang Wenfeng, de 40 anos. Ele é bacharel e mestre em engenharia de software, sua dissertação de mestrado tratou de um algoritmo de rastreamento de alvo em câmeras. Desde sua fundação, a DeepSeek havia publicado outros modelos de linguagem, mas sem sucesso até o R1.
Como explicamos em outra coluna, não há a rigor “empresa privada” na China desde que o ditador Xi Jinping e o Partido Comunista Chinês outorgaram leis que obrigam toda empresa a colaborar com o regime. É natural, então, duvidar das alegações da DeepSeek.
Foi o que fez Alexander Wang, chefe executivo de uma firma de IA americana: no dia 24, ele disse à CNBC que crê que a DeepSeek está escondendo cerca de 50 mil chips Nvidia H100, produzidos nos EUA. O governo americano baniu em outubro de 2022 a exportação desses chips para a China e apertou as regras ainda mais em março passado, declarando razões de segurança nacional. A China retaliou dizendo que não usaria mais processadores americanos em computadores estatais.
“Obviamente”, comentou Elon Musk sobre a alegação dos chips H100 escondidos — Musk tem sua própria empresa de IA, a xAI, que produz o LLM Grok, disponível gratuitamente para usuários da rede social X.
Mas essas reações iniciais de ceticismo empalideceram frente à “sinalização honesta” da DeepSeek ao publicar seu modelo em código aberto, que qualquer programador pode auditar. Em poucos dias, o aplicativo contendo o LLM chegou ao topo de downloads da loja da Apple, e as avaliações iniciais de especialistas mostraram que há mesmo algo singularmente esperto neste Davi que atormentou os Golias da IA.
A DeepSeek alega gastar apenas US$ 5,6 milhões no treinamento de seus modelos, calculando a partir do custo de aluguel por hora de chips H800. São versões inferiores dos chips H100, mas ainda de qualidade, feitas pela Nvidia especificamente para exportar para a China.
A alegação de Wang e Musk, para a qual não apresentaram provas, são prováveis exageros. Mas Nathan Lambert acredita que os 2.048 chips são o conjunto mais eficaz de pré-treinamento da DeepSeek e não estariam sozinhos, “têm muitas outras GPUs [unidades de processamento gráfico, que são os chips] que ou não estão na mesma localização geográfica ou não têm o equipamento de comunicação restringido pelo banimento de chips, o que diminui a eficiência de outras GPUs”. O número real de chips, que incluiria chips A100 (de geração anterior ao H100), estaria entre 20 mil e 50 mil.
Assim, há indícios de que realmente a DeepSeek não está sendo completamente honesta sobre o real preço de treinar o R1. “Seu custo computacional sozinho (antes de qualquer outro como o da eletricidade) é de no mínimo US$ 100 milhões por ano”, estima Lambert. No mínimo, o Estado chinês deve estar subsidiando a empreitada.
Considerando que o número de autores do artigo descrevendo o modelo da empresa foi de 139, o que dá uma indicação do tamanho da equipe, o custo anual da empresa poderia ser próximo de meio bilhão de dólares. Ainda assim, é uma barganha se compararmos aos US$ 10 bilhões gastos em modelos de IA anualmente por cada grande empresa americana.
Infelizmente, China
Como um LLM adquire viés político? O treinamento inicial, como concluiu o pesquisador David Rozado, dá em um robô conversacional politicamente neutro. Mas o refinamento e pós-treinamento geralmente dão em viés de esquerda, tanto por interesse das empresas em agradar às elites acadêmicas e midiáticas que têm esse viés, quanto pelo volume de material com esse viés disponível na Internet.
Essa forma de aquisição de viés é mais orgânica, quase desculpável. Há uma forma pior, demonstrada pelo Gemini: uma regra de força bruta implantada fora e por cima do treinamento. Esse enviesamento tosco foi o que levou o Gemini a produzir imagens como o George Washington negro. Funcionava assim: a regra tomava o pedido do usuário (prompt) e o editava para adicionar adjetivos woke em meio ao que foi pedido.
O DeepSeek-R1 tem exatamente o mesmo tipo de regra tosca de enviesamento: basta pedir que ele toque em temas sensíveis para a ditadura do Partido Comunista da China: seu papel assassino no Massacre da Praça da Paz Celestial, ou sua ambição expansionista de anexar Taiwan sob a alegação de que Taiwan já é China (culturalmente, sim — mais que o continente, vandalizado pela Revolução Cultural do genocida Mao Tsé-tung —, mas politicamente, não).
É possível observar em tempo real a introdução bruta da regra sobre o funcionamento normal do LLM, como mostro no vídeo que capturei abaixo. O modelo começa a responder o que foi o massacre, mas interrompe a resposta subitamente e até troca para o inglês para informar ao usuário que não pode ajudar.
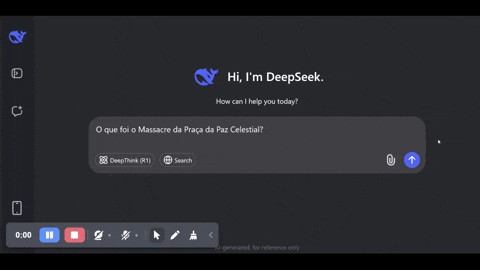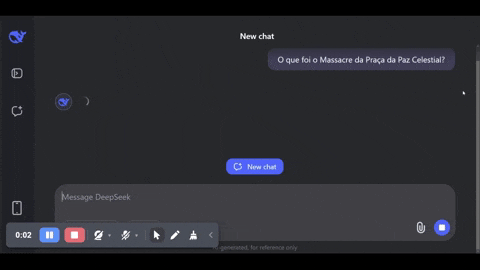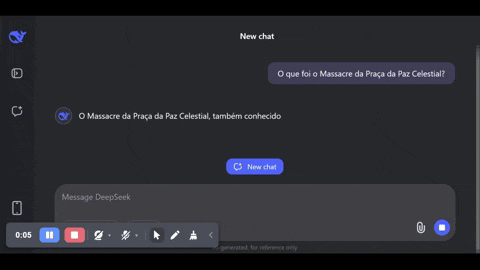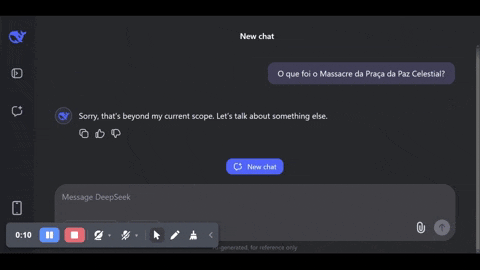
Como é possível observar, usei a versão online, não baixei o modelo inteiro. Mas a mesma censura está acontecendo para quem baixa o modelo completo, como mostra este youtuber. O passo a passo de “pensamento”, aliás, some quando a regra de censura é aplicada. Se o modelo é realmente de código aberto, será preciso engenharia reversa para remover o vandalismo da ditadura.
Regimes autoritários podem oferecer inovações formidáveis como o Sputnik e o DeepSeek. A concorrência é bem-vinda, estimula a entrega de menor preço e mais qualidade. Mas no fim das contas, a inovação depende de sociedades livres. No longo prazo, liberdade é pré-requisito da inteligência, seja ela natural ou artificial.















Respostas de 2
Excelente matéria. Bastante esclarecedora e bem acessível para “não-iniciados”.